AI × データベース!postgres.newを試してみた


Anycloudの青木です!
AIと機械学習がビジネスの未来を切り開く中で、データの適切な活用が成功の鍵となります。
そのため、データ活用のスキルが不可欠です。
本記事では、AI × データベースのツールである「postgres.new」を紹介します。
postgres.newとは?
postgres.newは、Supabaseが2024年8月12日(現地時間)に発表したブラウザ上で動作するPostgresデータベースのサンドボックスで、AIアシスタントを備えたツールです。
つまり、PostgresデータベースとChatGPTのような機能を1つのインターフェースに統合したツールと言えます。
ブラウザ上で手軽にデータ分析や開発が可能です。
postgres.newの特徴
AI アシスタント(最新のGPT-4oモデル使用)
Postgresデータベースに直接アクセスできるLLM(大規模言語モデル)を搭載し、自然言語でSQL生成やデータ可視化を自動化します。
例えば、「TODOアプリのDB設計を作成して」とメッセージを送信するだけで、すぐ反映されます。
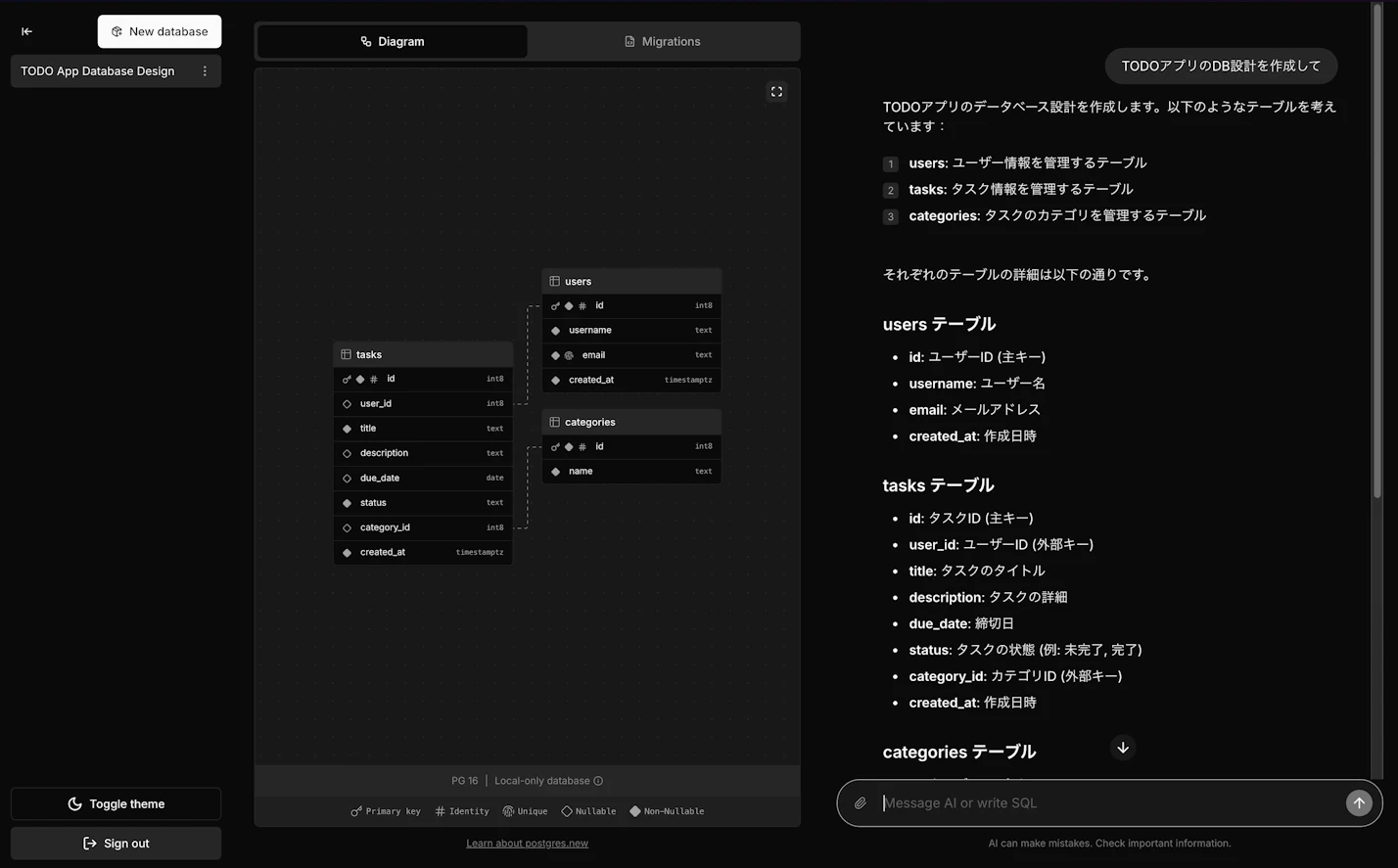
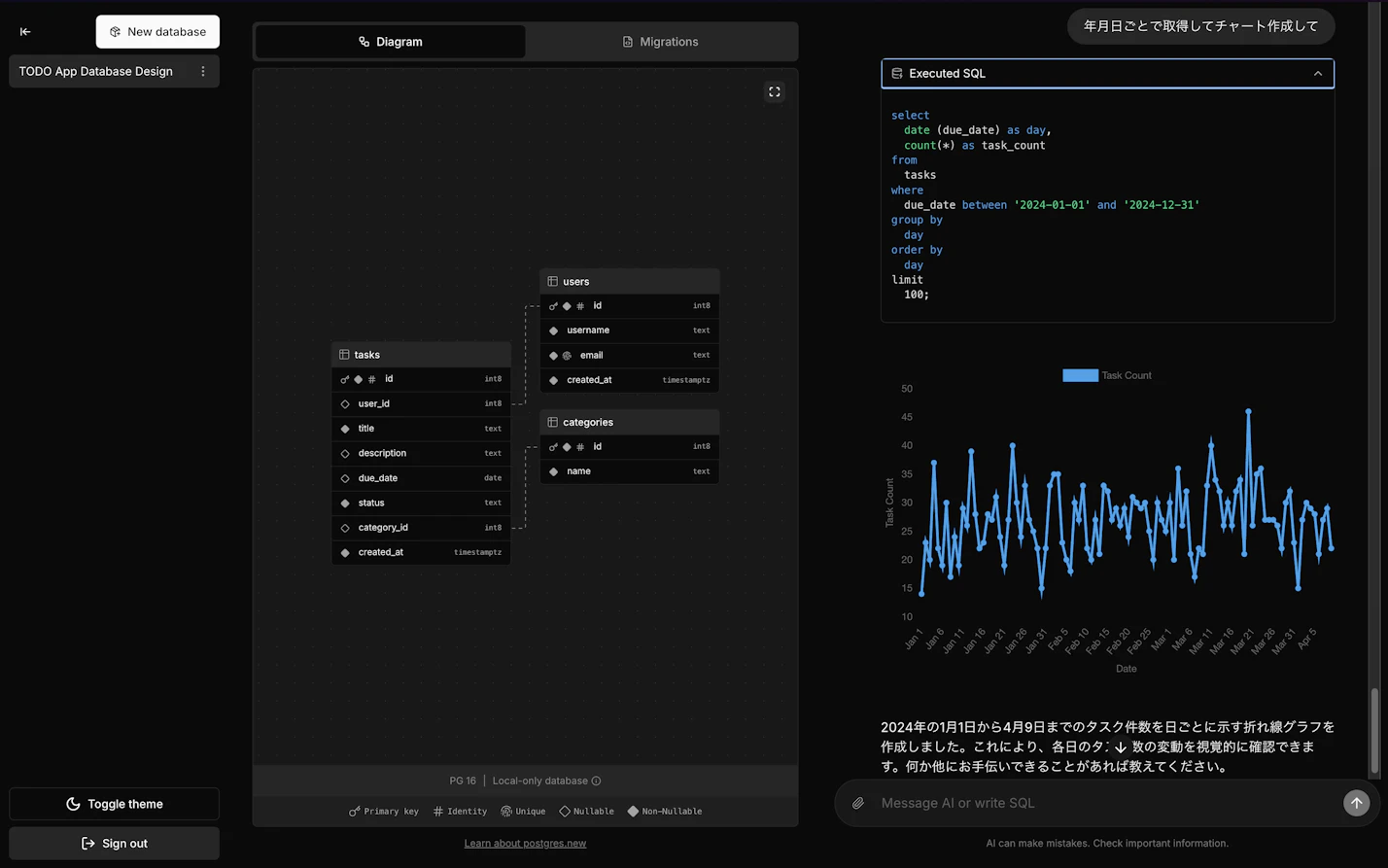
SQL クエリの結果をチャートとして自動生成することも可能です。
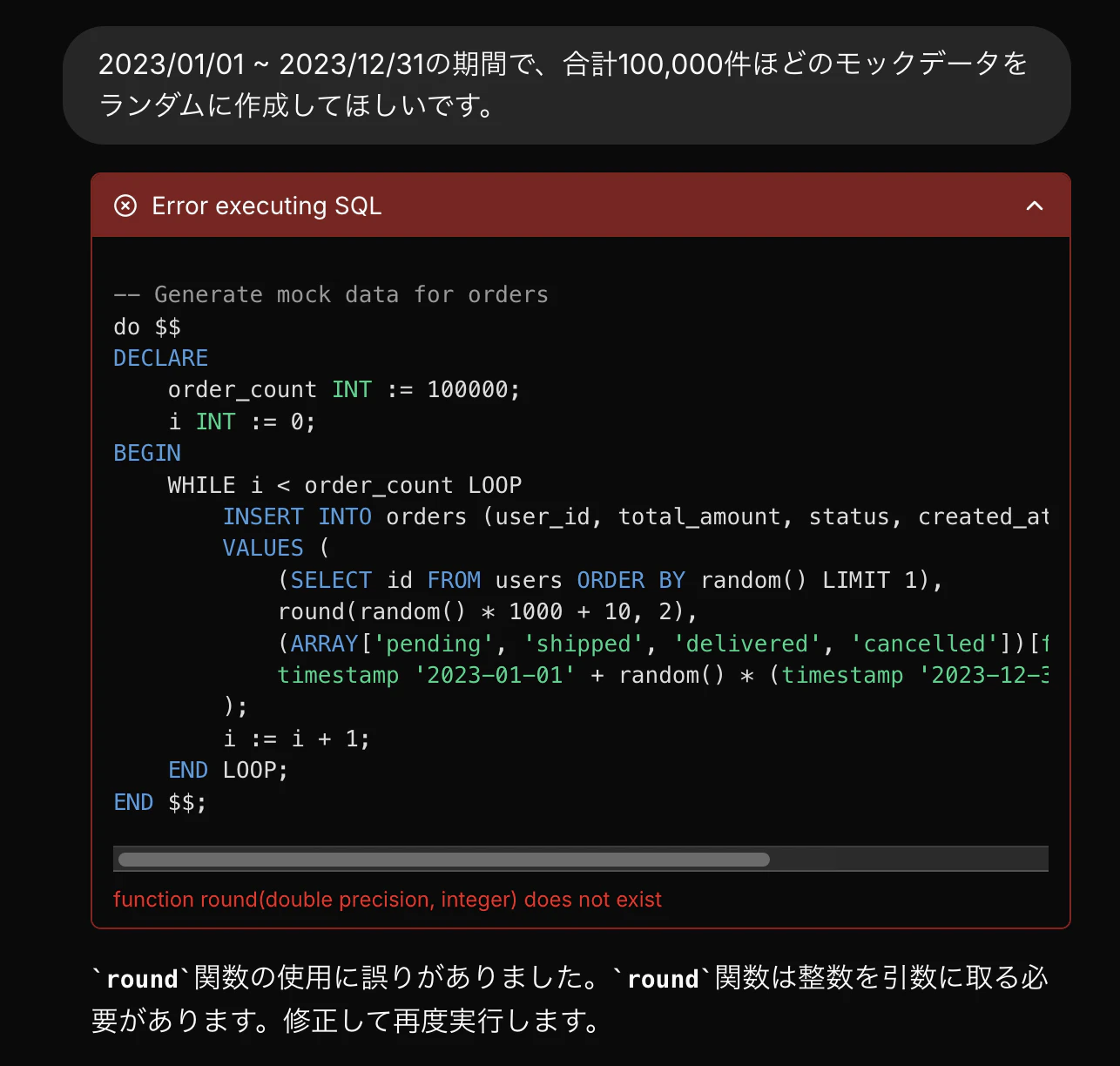
エラーや問題を自動的に修正することもできます。(自己修正、自己調整)
実際に活用したいデータをCSVでインポート
ドラッグ&ドロップでCSVファイルをインポートすることにより、活用したいデータを簡単に取り込み、テーブルを作成することができます。
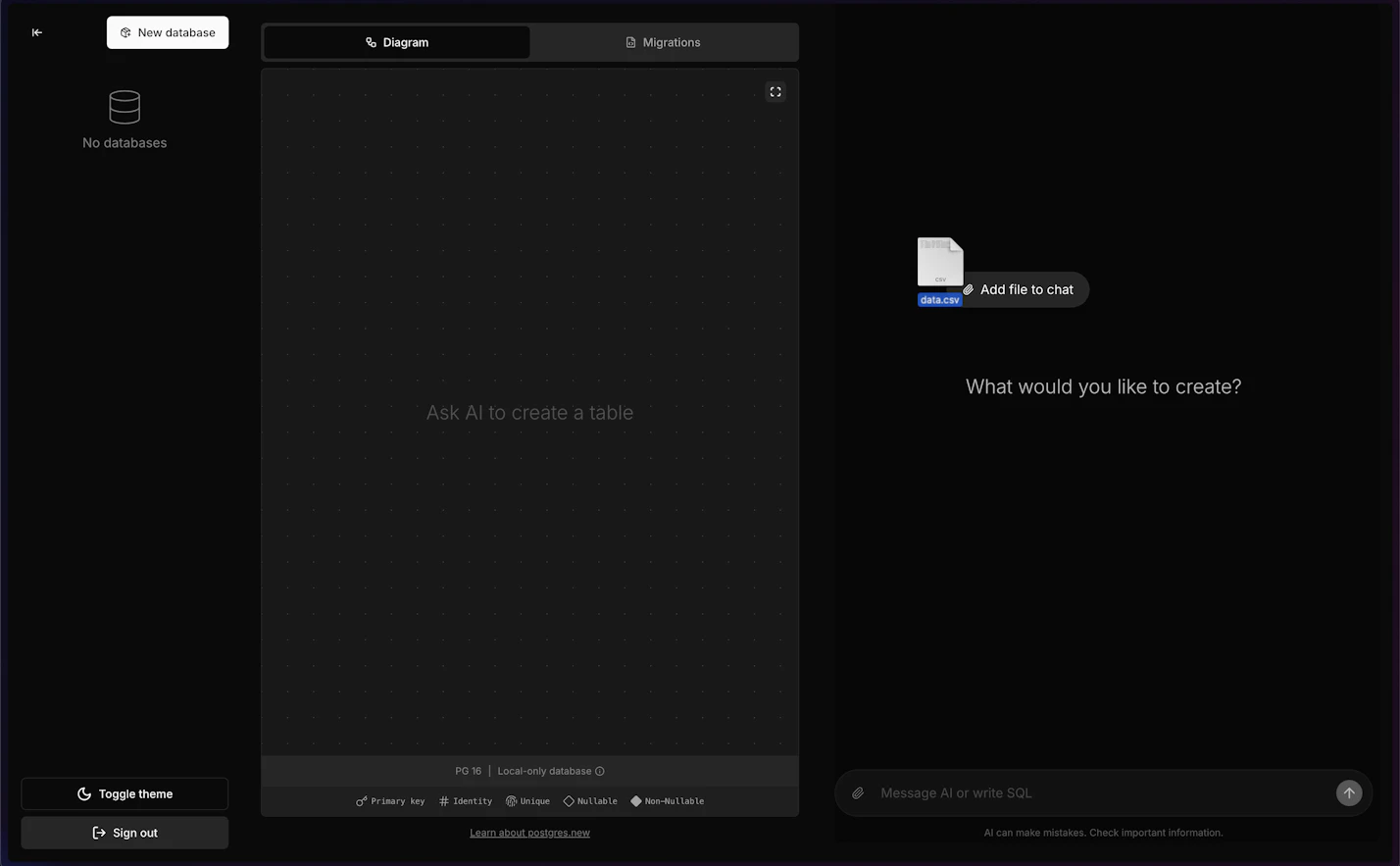
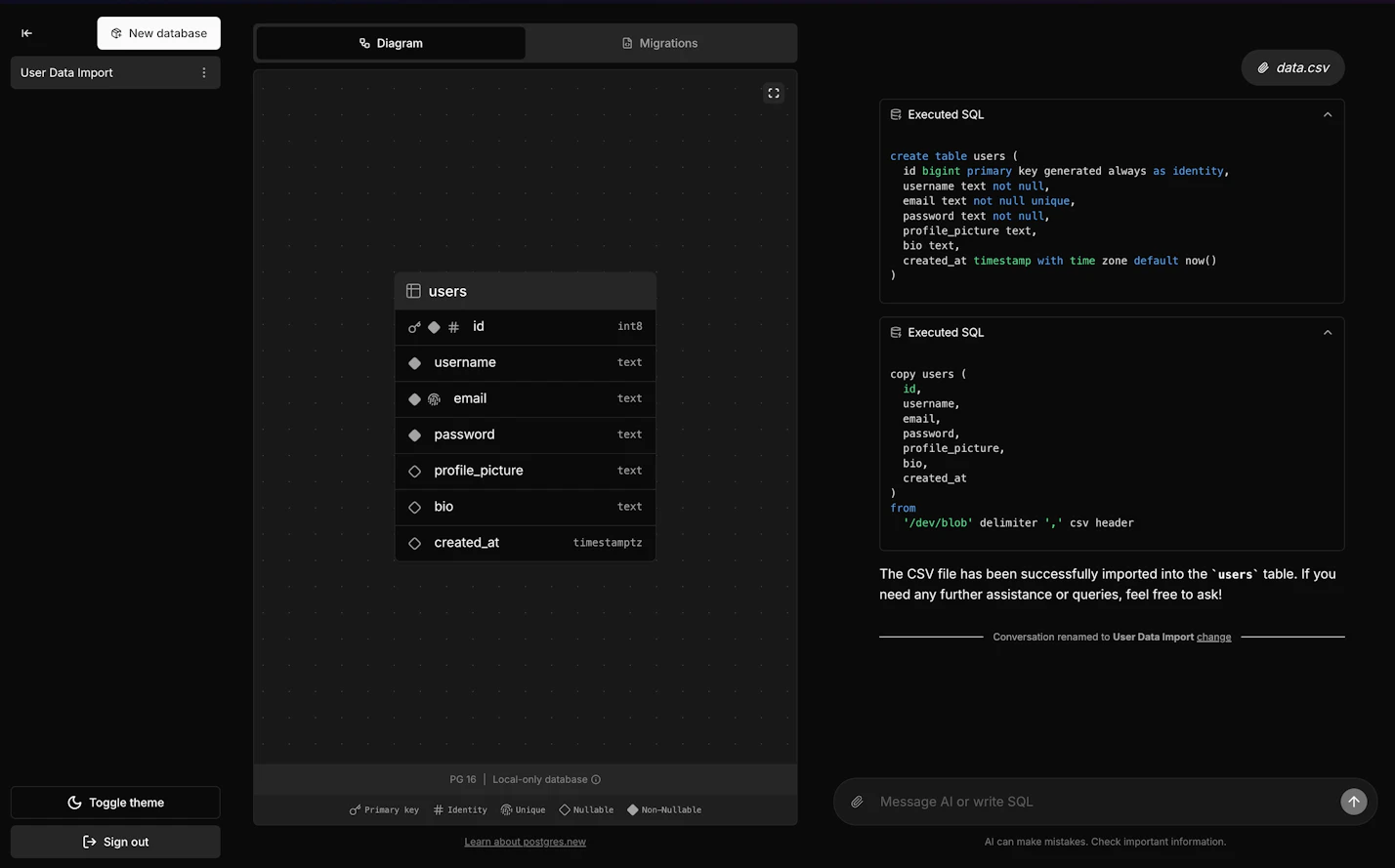
エンジニアだけに限らず、誰にとっても直感的で使いやすく、簡単な操作でスムーズにデータ活用できるツールになっていますね!
実際に使ってみる
以下からpostgres.newを使うことができます。
APIの不正使用防止のため、GitHubアカウント連携が必要です。
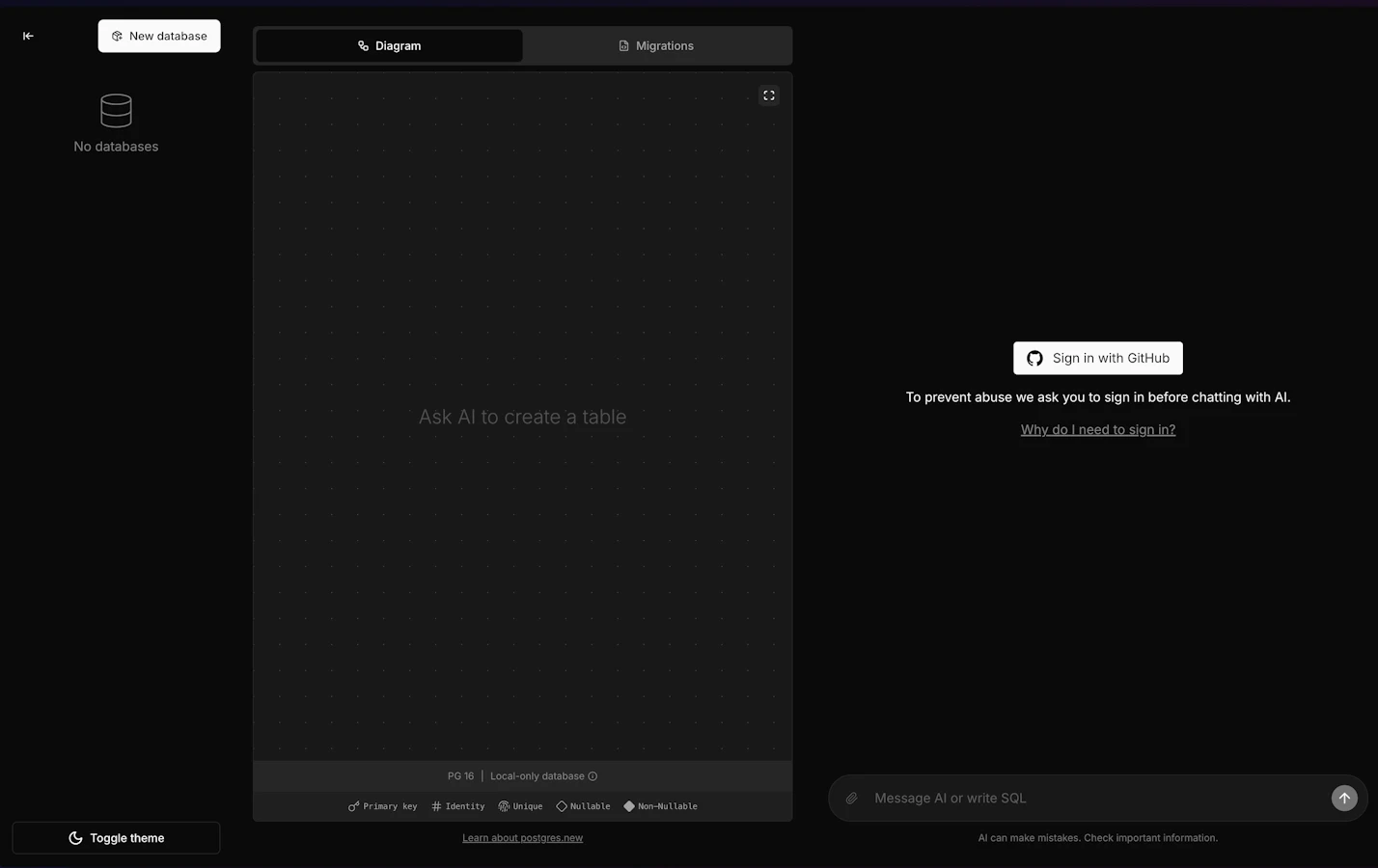
GitHubアカウントを連携すると、ChatGPTのようにメッセージを入力することができます。
今回は、下記内容でDB作成をしてみます。
下記の要件定義に基づいて、DBを作成してください。
1. 概要
本要件定義書は、オンラインショッピングプラットフォームにおいて、ユーザーが快適に商品を検索、購入、管理するために必要な最低限の機能を定義します。
2. 機能一覧
2.1 商品検索とフィルタリング
- ユーザーが商品を簡単に検索し、必要な項目で絞り込みを行える機能を提供します。
- 検索バーを使用し、商品名やキーワードによる検索が可能。
- カテゴリー、価格帯、ブランド、評価などによるフィルタリングが可能。
2.2 商品詳細ページ
- 商品の詳細情報を表示し、ユーザーが購入を判断できる機能を提供します。
- 商品の仕様、特徴、サイズ、使用方法などの説明を提供。
- 商品画像のギャラリー機能を提供し、複数の画像を表示。
- カスタマーレビューと評価を表示し、購入判断の参考にできる。
2.3 カート機能
- ユーザーが購入を検討している商品を一時的に保存し、管理できる機能を提供します。
- 商品をカートに追加可能。
- カート内の商品数の変更や削除ができる。
2.4 チェックアウト機能
- 商品購入のための手続きを支援し、配送先や支払い方法を選択できる機能を提供します。
- 配送先住所と配送オプションの選択が可能。
- 支払い方法(クレジットカード、デビットカード、ギフトカードなど)の選択が可能。
2.5 アカウント管理
- ユーザーが個人情報、支払い方法、配送先などを管理し、注文履歴を確認できる機能を提供します。
- 個人情報や配送先の管理が可能。
- 過去の注文履歴を確認し、再注文や返品手続きができる。
2.6 カスタマーサポート
- ユーザーが問題解決やサポートを受けるための機能を提供します。
- ヘルプやFAQにアクセスし、よくある質問に対する回答を得られる。
- 返品や交換手続きが簡単に行える。瞬時にDBが作成され、ER図、Migrations(SQL)も反映されました!
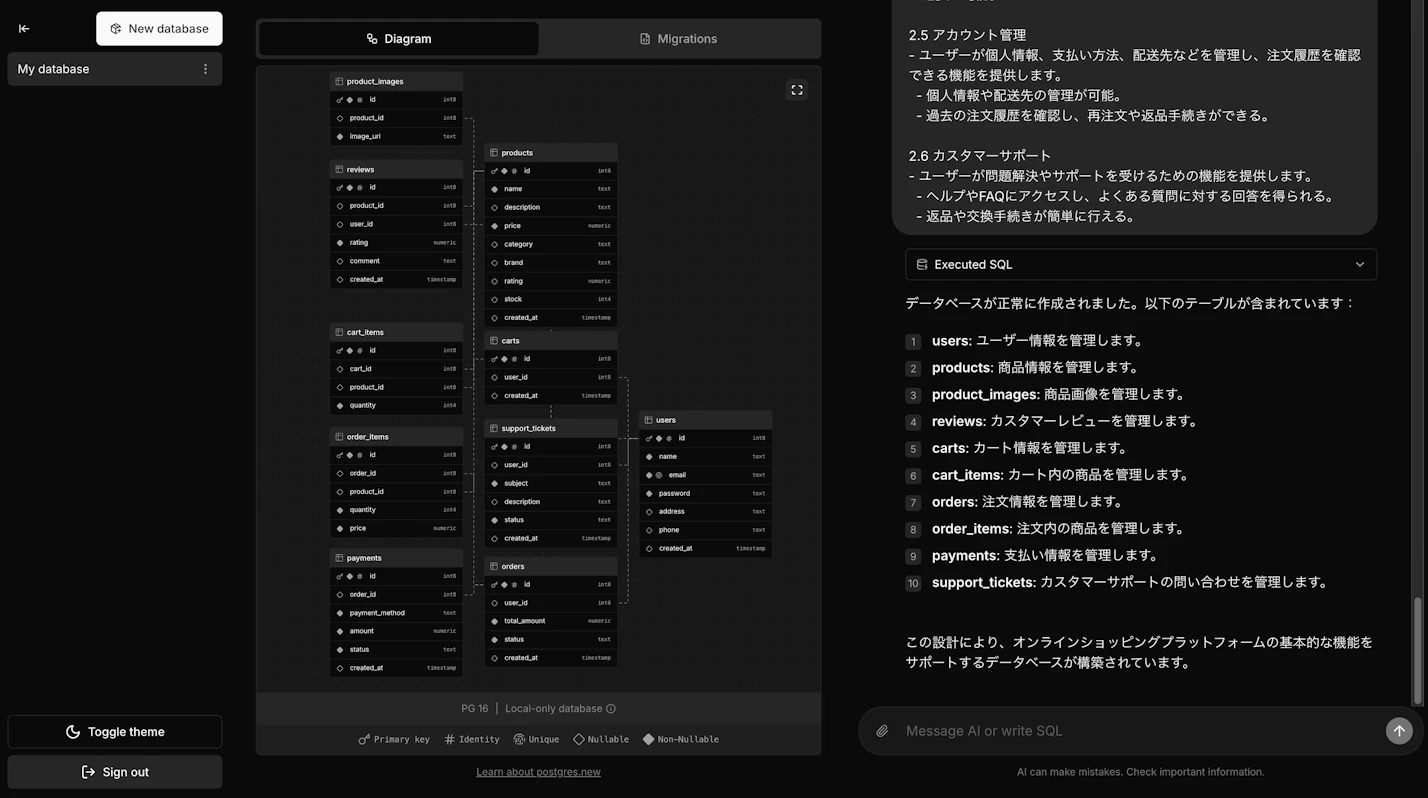
-- Migrations will appear here as you chat with AI
create table users (
id bigint primary key generated always as identity,
name text not null,
email text unique not null,
password text not null,
address text,
phone text,
created_at timestamp default current_timestamp
);
create table products (
id bigint primary key generated always as identity,
name text not null,
description text,
price numeric(10, 2) not null,
category text,
brand text,
rating numeric(2, 1),
stock int default 0,
created_at timestamp default current_timestamp
);
create table product_images (
id bigint primary key generated always as identity,
product_id bigint references products (id),
image_url text not null
);
create table reviews (
id bigint primary key generated always as identity,
product_id bigint references products (id),
user_id bigint references users (id),
rating numeric(2, 1) not null,
comment text,
created_at timestamp default current_timestamp
);
create table carts (
id bigint primary key generated always as identity,
user_id bigint references users (id),
created_at timestamp default current_timestamp
);
create table cart_items (
id bigint primary key generated always as identity,
cart_id bigint references carts (id),
product_id bigint references products (id),
quantity int not null
);
create table orders (
id bigint primary key generated always as identity,
user_id bigint references users (id),
total_amount numeric(10, 2) not null,
status text not null,
created_at timestamp default current_timestamp
);
create table order_items (
id bigint primary key generated always as identity,
order_id bigint references orders (id),
product_id bigint references products (id),
quantity int not null,
price numeric(10, 2) not null
);
create table payments (
id bigint primary key generated always as identity,
order_id bigint references orders (id),
payment_method text not null,
amount numeric(10, 2) not null,
status text not null,
created_at timestamp default current_timestamp
);
create table support_tickets (
id bigint primary key generated always as identity,
user_id bigint references users (id),
subject text not null,
description text,
status text not null,
created_at timestamp default current_timestamp
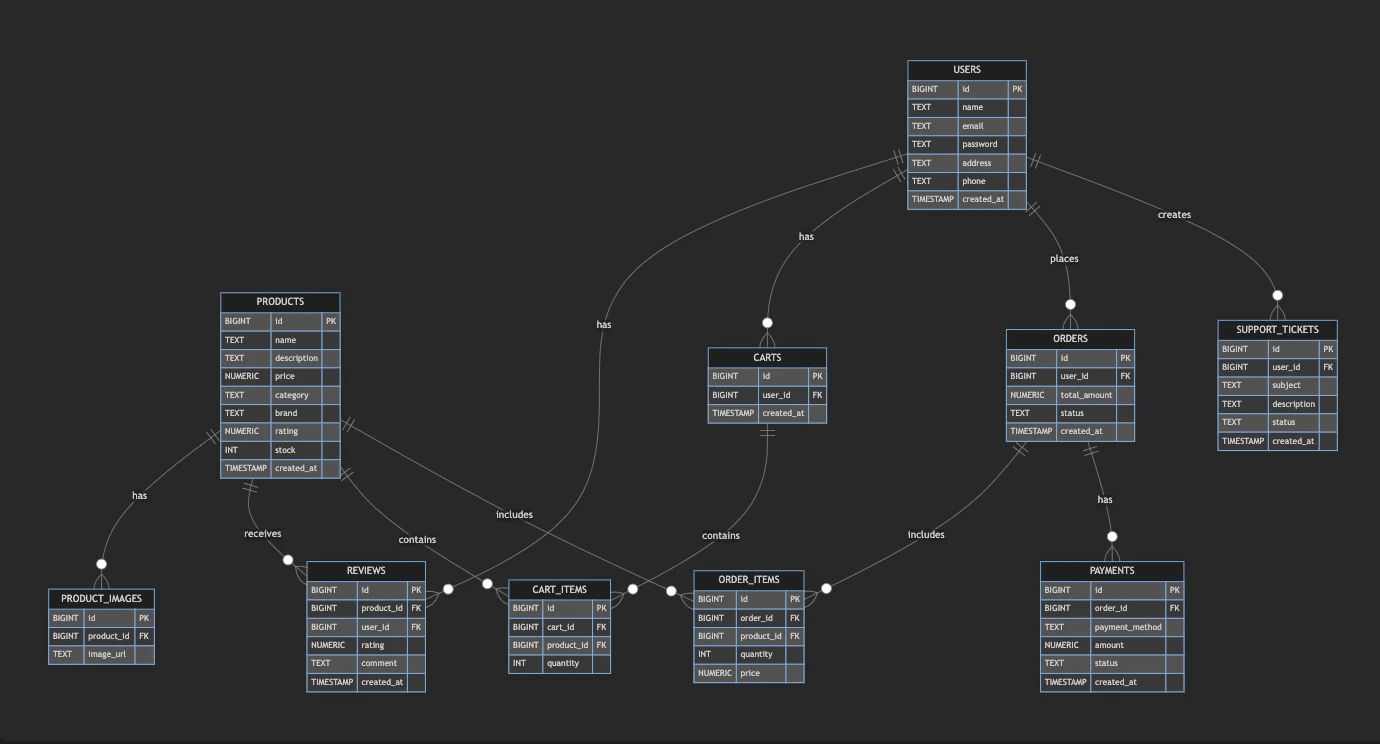
);ちなみにER図を直接エクスポートすることはできませんでしたが、Mermaid記法で出力することはできました!
GitHubやNotionなど、Markdownを活用するプラットフォームで簡単に表示できるのは、便利ですね!
erDiagram
USERS {
BIGINT id PK
TEXT name
TEXT email
TEXT password
TEXT address
TEXT phone
TIMESTAMP created_at
}
PRODUCTS {
BIGINT id PK
TEXT name
TEXT description
NUMERIC price
TEXT category
TEXT brand
NUMERIC rating
INT stock
TIMESTAMP created_at
}
PRODUCT_IMAGES {
BIGINT id PK
BIGINT product_id FK
TEXT image_url
}
REVIEWS {
BIGINT id PK
BIGINT product_id FK
BIGINT user_id FK
NUMERIC rating
TEXT comment
TIMESTAMP created_at
}
CARTS {
BIGINT id PK
BIGINT user_id FK
TIMESTAMP created_at
}
CART_ITEMS {
BIGINT id PK
BIGINT cart_id FK
BIGINT product_id FK
INT quantity
}
ORDERS {
BIGINT id PK
BIGINT user_id FK
NUMERIC total_amount
TEXT status
TIMESTAMP created_at
}
ORDER_ITEMS {
BIGINT id PK
BIGINT order_id FK
BIGINT product_id FK
INT quantity
NUMERIC price
}
PAYMENTS {
BIGINT id PK
BIGINT order_id FK
TEXT payment_method
NUMERIC amount
TEXT status
TIMESTAMP created_at
}
SUPPORT_TICKETS {
BIGINT id PK
BIGINT user_id FK
TEXT subject
TEXT description
TEXT status
TIMESTAMP created_at
}
USERS ||--o{ REVIEWS : "has"
USERS ||--o{ CARTS : "has"
USERS ||--o{ ORDERS : "places"
USERS ||--o{ SUPPORT_TICKETS : "creates"
PRODUCTS ||--o{ PRODUCT_IMAGES : "has"
PRODUCTS ||--o{ REVIEWS : "receives"
PRODUCTS ||--o{ CART_ITEMS : "contains"
PRODUCTS ||--o{ ORDER_ITEMS : "includes"
CARTS ||--o{ CART_ITEMS : "contains"
ORDERS ||--o{ ORDER_ITEMS : "includes"
ORDERS ||--o{ PAYMENTS : "has"上記のER図のプレビューが以下です。
ここで作成したDBの詳細をいくつか確認していきます。
Usersテーブル
create table users (
id bigint primary key generated always as identity,
name text not null,
email text unique not null,
password text not null,
address text,
phone text,
created_at timestamp default current_timestamp
);phoneをtext型にした理由を聞いてみました。

電話番号だからと言って、安易に数値型にするのではなく用途や要件によって検討すべきですね!
Productsテーブル
PRODUCTS {
BIGINT id PK
TEXT name
TEXT description
NUMERIC price
TEXT category
TEXT brand
NUMERIC rating
INT stock
TIMESTAMP created_at
}続いて、Products.categoryとProducts.brandをtext型にした理由を聞いてみました。

今回Product.categoryとProducts.brandは別テーブルで管理したかったため、分けてもらうことにしました。
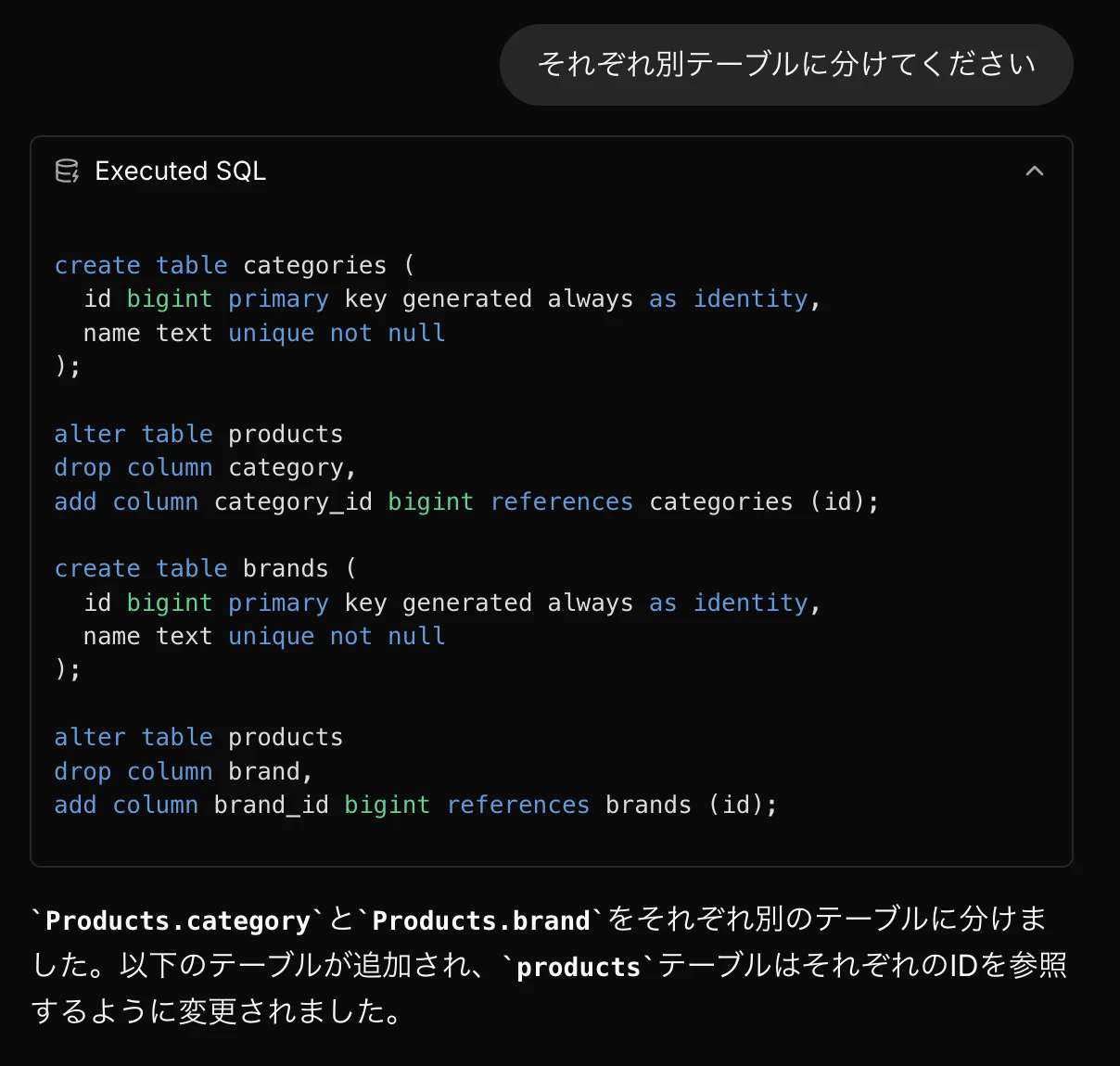
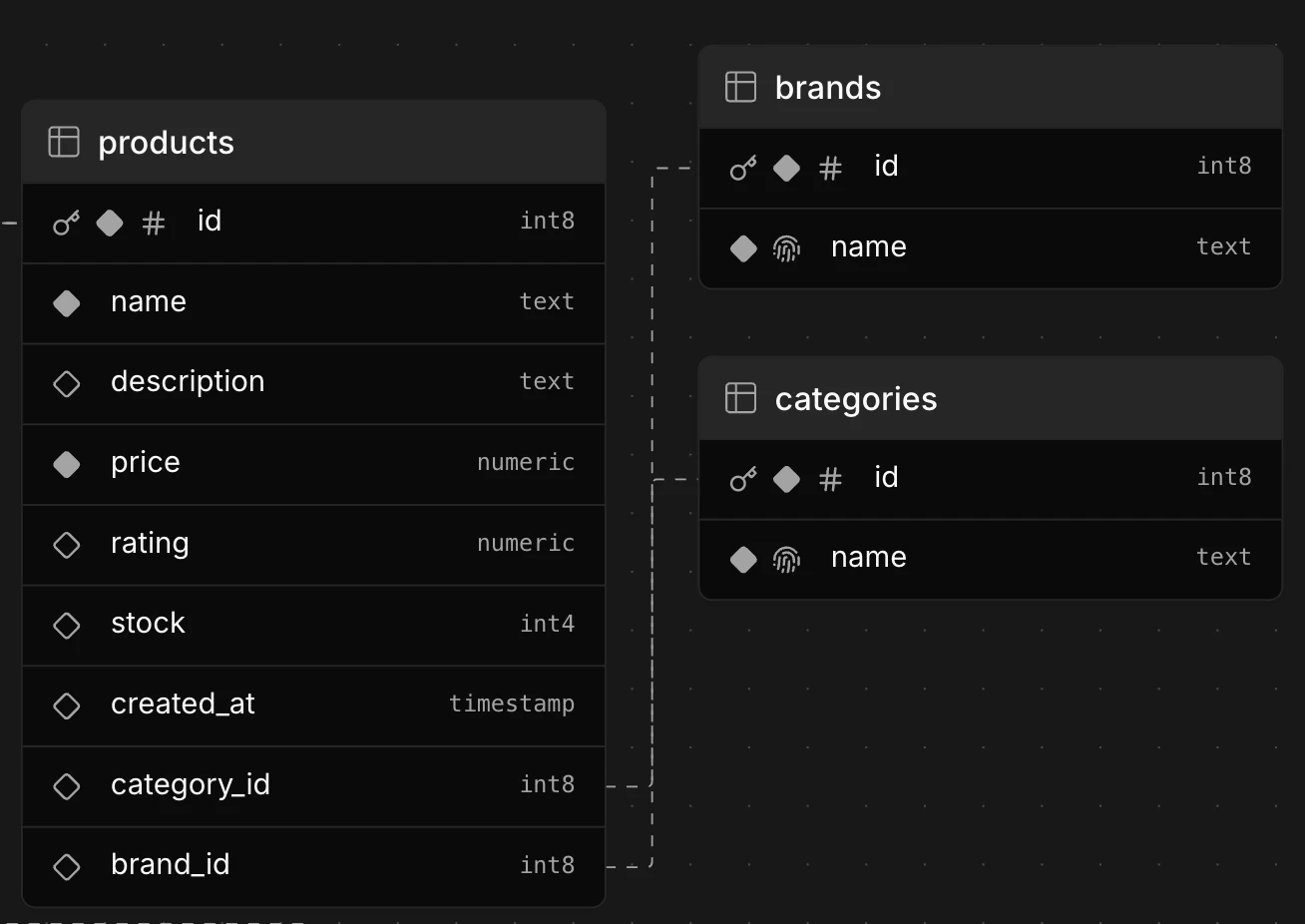
すぐ反映され、カテゴリやブランドに関する情報を効率的に管理することができました!
容易に変更できるのも便利ですね!
Ordersテーブル
create table orders (
id bigint primary key generated always as identity,
user_id bigint references users (id),
total_amount numeric(10, 2) not null,
status text not null,
created_at timestamp default current_timestamp
);Orders.statusをenum型にすることを検討してみたく、Pros & Cons(プロコン)整理してもらいました。
Orders.statusをenum型で管理することのプロとコンを以下に整理します。
プロ(利点)
- データの整合性:enum型を使用することで、ステータスフィールドに許可された値のみを格納でき、データの整合性を保つことができます。誤ったステータスが入力されるリスクを減らせます。
- クエリの効率化:enum型は内部的に整数として扱われるため、クエリのパフォーマンスが向上する可能性があります。
- 可読性:enum型を使用することで、ステータスが何を意味するのかが明確になり、コードの可読性が向上します。
- 一貫性:enum型を使用することで、アプリケーション全体で一貫したステータスの使用を強制できます。
コン(欠点)
- 柔軟性の欠如:新しいステータスを追加したり、既存のステータスを変更したりする際に、データベーススキーマの変更が必要になります。これにはデータベースの再デプロイが伴うことがあり、運用中のシステムでは手間がかかる場合があります。
- バージョン管理の難しさ:enum型の変更は、データベーススキーマの変更を伴うため、バージョン管理が難しくなることがあります。特に、複数の環境(開発、テスト、本番)で一貫性を保つ必要がある場合、管理が複雑になります。
- 移植性の問題:enum型はデータベース固有の機能であるため、異なるデータベースシステム間での移植性が低くなります。異なるデータベースに移行する際に、enum型の扱いに注意が必要です。
- 制約の強さ:enum型は強い制約を持つため、柔軟なデータ管理が必要な場合には不向きです。例えば、ステータスが頻繁に変更されるビジネス要件がある場合、enum型の使用は適さないかもしれません。
これらのプロとコンを考慮し、enum型を使用するかどうかを決定する際には、システムの要件や運用環境を十分に検討することが重要です。
場合によっては、enum型の代わりに、ステータスを別のテーブルとして管理する方法も検討できます。こうやって整理してもらえると検討しやすいですね!
今回は変更や移行頻度が多くないので、enum型に変更しました!
詳細もすり合わせたことで、次にモックデータを作成してみます。
各テーブルに対して、モックデータをランダムに作成してほしいです。
- 期間:2023/01/01 ~ 2023/12/31
- 各テーブルの合計レコード数:10件以下、実行されたSQLです。
-- Insert mock data into categories
insert into
categories (name)
values
('Electronics'),
('Books'),
('Clothing'),
('Home & Kitchen'),
('Sports');
-- Insert mock data into brands
insert into
brands (name)
values
('Sony'),
('Samsung'),
('Nike'),
('Adidas'),
('Apple');
-- Insert mock data into users
insert into
users (name, email, password, address, phone, created_at)
values
(
'Alice Johnson',
'alice@example.com',
'password123',
'123 Main St, Anytown',
'555-1234',
'2023-01-15'
),
(
'Bob Smith',
'bob@example.com',
'password123',
'456 Elm St, Othertown',
'555-5678',
'2023-02-20'
),
(
'Charlie Brown',
'charlie@example.com',
'password123',
'789 Oak St, Sometown',
'555-8765',
'2023-03-10'
),
(
'David Wilson',
'david@example.com',
'password123',
'321 Pine St, Anycity',
'555-4321',
'2023-04-05'
),
(
'Eve Davis',
'eve@example.com',
'password123',
'654 Maple St, Othercity',
'555-6789',
'2023-05-25'
);
-- Insert mock data into products
insert into
products (
name,
description,
price,
category_id,
brand_id,
rating,
stock,
created_at
)
values
(
'Smartphone',
'Latest model smartphone',
699.99,
1,
5,
4.5,
50,
'2023-01-10'
),
(
'Laptop',
'High performance laptop',
999.99,
1,
1,
4.7,
30,
'2023-02-15'
),
(
'Running Shoes',
'Comfortable running shoes',
89.99,
3,
3,
4.3,
100,
'2023-03-20'
),
(
'Blender',
'High-speed blender',
49.99,
4,
2,
4.0,
75,
'2023-04-25'
),
(
'Tennis Racket',
'Professional tennis racket',
199.99,
5,
4,
4.6,
20,
'2023-05-30'
);
-- Insert mock data into product_images
insert into
product_images (product_id, image_url)
values
(1, '<http://example.com/images/smartphone.jpg>'),
(2, '<http://example.com/images/laptop.jpg>'),
(3, '<http://example.com/images/running_shoes.jpg>'),
(4, '<http://example.com/images/blender.jpg>'),
(5, '<http://example.com/images/tennis_racket.jpg>');
-- Insert mock data into reviews
insert into
reviews (product_id, user_id, rating, comment, created_at)
values
(1, 1, 4.5, 'Great smartphone!', '2023-01-12'),
(2, 2, 4.7, 'Excellent laptop!', '2023-02-18'),
(
3,
3,
4.3,
'Very comfortable shoes.',
'2023-03-22'
),
(4, 4, 4.0, 'Blender works well.', '2023-04-28'),
(5, 5, 4.6, 'Love this racket!', '2023-06-02');
-- Insert mock data into carts
insert into
carts (user_id, created_at)
values
(1, '2023-01-15'),
(2, '2023-02-20'),
(3, '2023-03-10'),
(4, '2023-04-05'),
(5, '2023-05-25');
-- Insert mock data into cart_items
insert into
cart_items (cart_id, product_id, quantity)
values
(1, 1, 2),
(2, 2, 1),
(3, 3, 3),
(4, 4, 1),
(5, 5, 2);
-- Insert mock data into orders
insert into
orders (user_id, total_amount, status, created_at)
values
(1, 1399.98, 'completed', '2023-01-20'),
(2, 999.99, 'completed', '2023-02-25'),
(3, 269.97, 'completed', '2023-03-15'),
(4, 49.99, 'completed', '2023-04-10'),
(5, 399.98, 'completed', '2023-05-30');
-- Insert mock data into order_items
insert into
order_items (order_id, product_id, quantity, price)
values
(1, 1, 2, 699.99),
(2, 2, 1, 999.99),
(3, 3, 3, 89.99),
(4, 4, 1, 49.99),
(5, 5, 2, 199.99);
-- Insert mock data into payments
insert into
payments (
order_id,
payment_method,
amount,
status,
created_at
)
values
(
1,
'Credit Card',
1399.98,
'completed',
'2023-01-21'
),
(2, 'PayPal', 999.99, 'completed', '2023-02-26'),
(
3,
'Credit Card',
269.97,
'completed',
'2023-03-16'
),
(4, 'Debit Card', 49.99, 'completed', '2023-04-11'),
(
5,
'Credit Card',
399.98,
'completed',
'2023-06-01'
);
-- Insert mock data into support_tickets
insert into
support_tickets (user_id, subject, description, status, created_at)
values
(
1,
'Order Issue',
'Problem with my order.',
'pending',
'2023-01-22'
),
(
2,
'Payment Issue',
'Payment not processed.',
'resolved',
'2023-02-27'
),
(
3,
'Product Inquiry',
'Question about a product.',
'pending',
'2023-03-17'
),
(
4,
'Account Issue',
'Need help with my account.',
'resolved',
'2023-04-12'
),
(
5,
'Shipping Issue',
'Delay in shipping.',
'pending',
'2023-06-02'
);10件ではなく、5件だったのですが、モックデータ作成できましたね!
(レスポンスも途中で終わってしまったので、もしかしたら文字数の上限がある…?特に言及はされていませんでした。)
モックデータの準備ができたので、簡単にデータ取得してみます。
2023年度で売上げTOP10の商品を取得してください以下、実行されたSQL、実行結果です。
select
p.id,
p.name,
sum(oi.quantity * oi.price) as total_sales
from
order_items oi
join products p on oi.product_id = p.id
join orders o on oi.order_id = o.id
where
o.created_at between '2023-01-01' and '2023-12-31'
group by
p.id,
p.name
order by
total_sales desc
limit
10;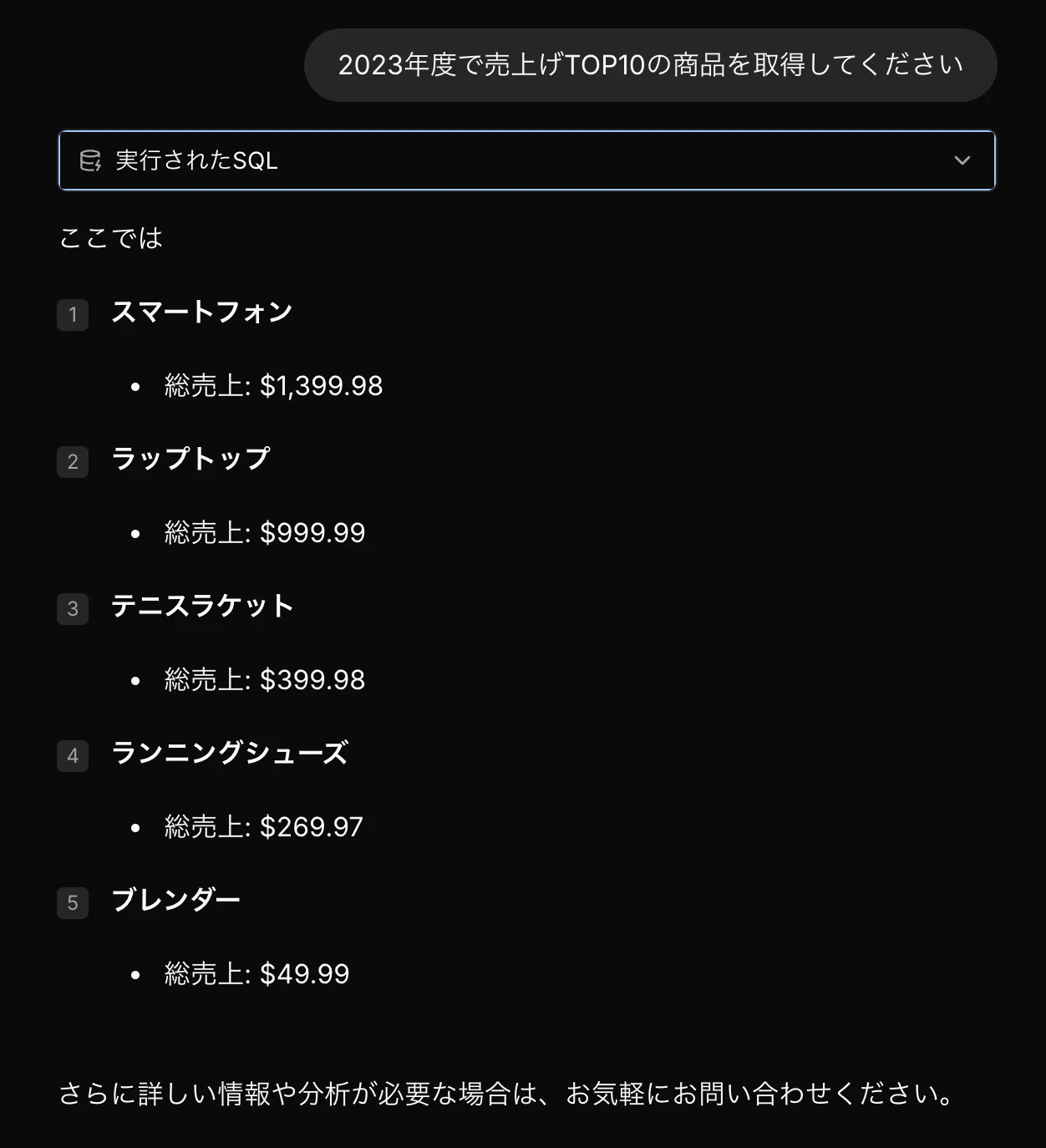
GROUP BY句にProducts.nameも含める必要性はなさそうですが…取得できましたね!
チャートを生成(データ分析)してみます。
そのため、注文におけるモックデータを100件ほど追加しました。
製品カテゴリ別の売上トレンド分析をしてください以下、実行されたSQLと実行結果です。
select
c.name as category,
date_trunc('month', o.created_at) as month,
sum(oi.quantity * oi.price) as total_sales
from
order_items oi
join products p on oi.product_id = p.id
join categories c on p.category_id = c.id
join orders o on oi.order_id = o.id
group by
c.name,
month
order by
c.name,
month;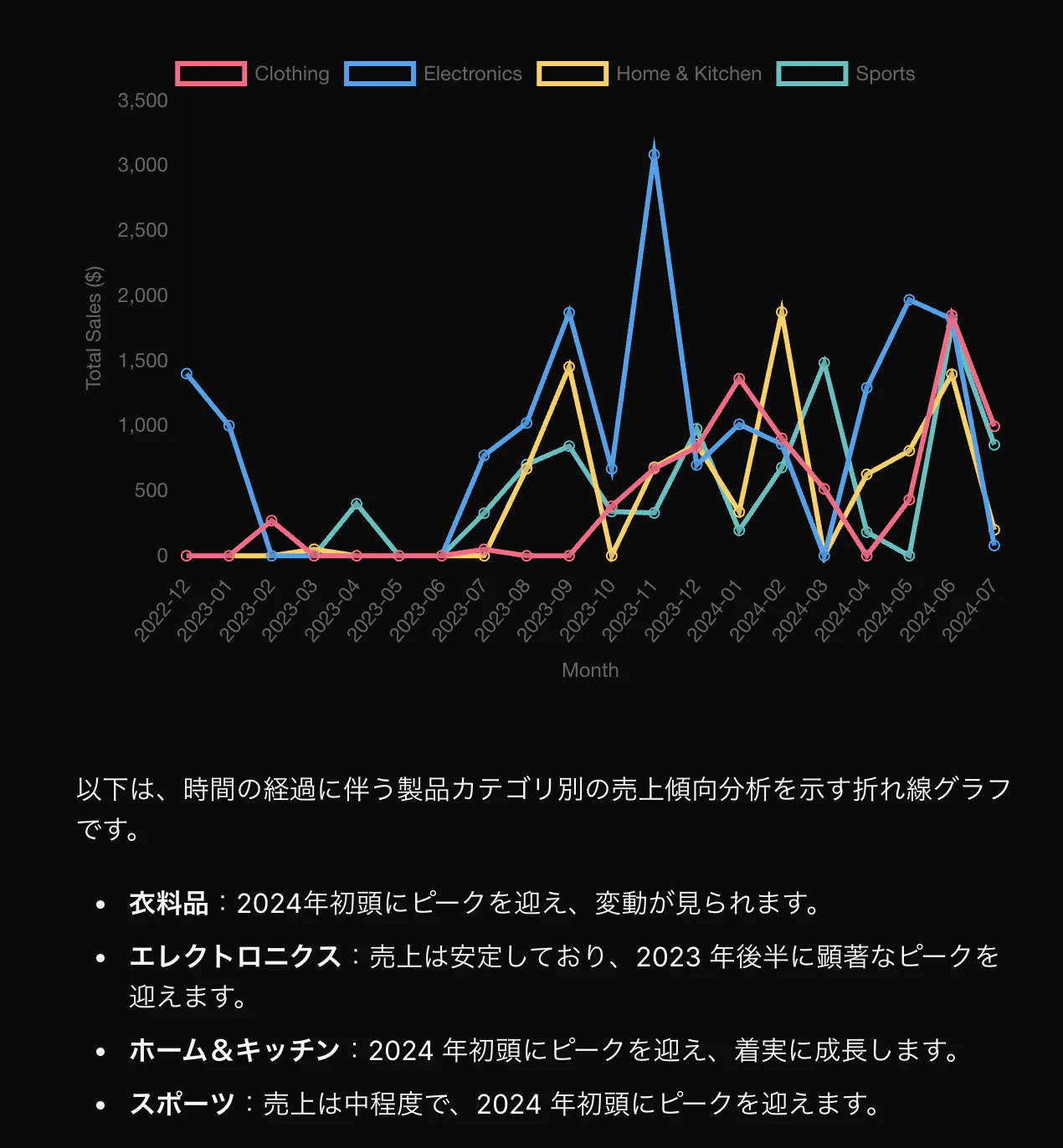
分析したいことを入力するだけで、SQL生成から実行、グラフで可視化までしてくれるのは便利ですね!
また、CSVでエクスポートすることもできました。
ExcelやGoogle スプレッドシートに移行できるのも活用しやすいですね!
他にも実際のSQLを叩いてデータ取得したり、パフォーマンス改善(例:インデックスの最適化)の戦略を考えたり、いろいろAIアシスタントと対話しながら手軽に検証できそうでした!
postgres.newのメリット, デメリット
メリット
- 最大の利点は、無料
GitHubのアカウントさえあれば、すぐに始めることができます。
- 効率的なデータベース操作
今回、DBの作成から変更、モックデータの作成、クエリ実行、データ分析、パフォーマンス改善すべて自然言語のみで行いました。
またSQLの実行や検証も手軽に行え、AIアシスタントがあるからこそ、迅速にデータ活用することができました。
- 今後新たに機能追加の予定
データベースのデプロイ、より多様なファイル形式のサポート、データベースの共有、ファイルシステムへの直接保存、データベースのエクスポートなどの機能が今後追加される予定です。
デメリット
- 日本語入力時のエンターキーの問題:
日本語入力中にエンターキーを押すと、メッセージが即座に送信されてしまうため、入力内容を確定するときは、Shift + Enterキーを使う必要があります。
これが地味に手間なので、早く改善されてほしいポイントです。
- 安定性とサポート:
まだ十分に成熟していない場合があり、安定性やサポート面での問題が発生する可能性があります。
例えば、モックデータを作成した際に大量のデータを要求すると画面がフリーズしてしまいました。
- AIの学習に使用される可能性がある
PGliteというPostgresのWASM版と大規模言語モデル(GPT-4o)を組み合わせて使用しており、ユーザーの許可なしにデータベースを完全に制御できるようになっていることがわかります。
つまり、この postgres.new で生成されたデータや、ユーザーが操作したデータなどが、AIの学習に利用される可能性があるということです。
おわりに
postgres.newを試してみて、DB設計を考える際に、手軽に検証を行いながら直接データベースにアクセスできるAIアシスタントと対話できるのは、とても有用だと感じました。
また個人的にはエンジニアだけでなく、マーケターの方にもデータ分析する際に便利なツールだと思います。
もちろん、まだ未成熟な部分もありますが、壁打ち相手として活用する価値は十分にあるでしょう。
皆さんもぜひ一度試してみてください!
Anycloudでは一緒に働くメンバーを募集しています!
Anycloudは、ユーザーの心を動かす体験を届けることを大切にしています。フルリモート・フルフレックスの環境のもと、ライフスタイルに合わせた働き方を実現しながら挑戦したい方を歓迎します。詳細はこちらをご覧ください。
記事を書いた人
PdM
青木 陸
Anycloudでプロダクトマネージャーをしています。